

新闻资讯
质量为本、客户为根、勇于拼搏、务实创新
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。
目前,模式匹配原理已经被应用于大多数语音识别系统中。一般的模式识别包括预处理,特征提取,模式匹配等基本模块。首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。常用的特征参数包括:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC)等。在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。
语音识别,以目前的主流ASR-自动语音/语言识别技术为例,实现的功能是把音频波形(模拟信号)转换为文字(符号)。其原理可以理解为一个计算机系统,输入语音,并分解为词、字、音节等元素,通过与软件内部存储好的特征元素(模型)进行模式匹配,找到最可能接近的文字、词语或语句并输出。
ASR方法是建立在概率论与统计学科上。这与人类对话交流的过程有异同:区别在于人类对话时,声音是通过耳朵进入大脑直接处理,不需要转变成文字,否则文盲就不能与他人沟通,事实并非如此;相同点是都需要一个学习的过程,幼儿学说话是个反复强化记忆的过程,ASR的模型也需要语料的训练,得到一个合适参数的模型结构用来推理。
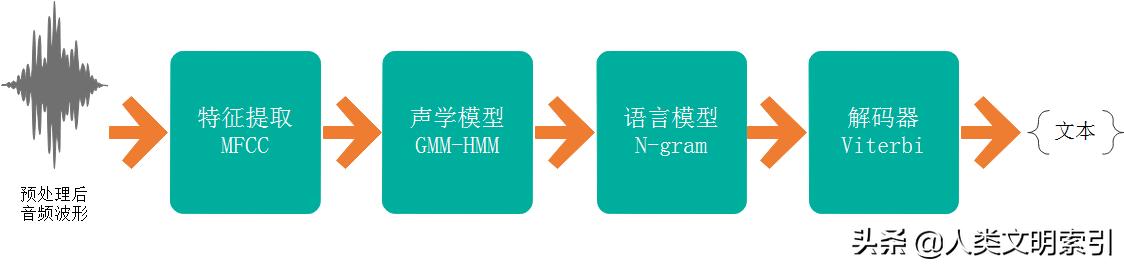
特征提取:经典的MFCC梅尔频率倒谱系数法——对输入端的经过增强、去噪等预处理后的音频波形文件进行特征提取,主要是滤波、截断(分帧)、加窗、快速傅立叶变换FFT等信号处理操作,得到短时语音信号的功率谱,再经过三角窗滤波、log对数、离散预选DCT、谱加权、倒谱均值减CMS、一二阶差分等操作,得到特征矢量,即可观测的词条序列;
假设最终期望识别得到的词条序列是。需要成立一个语音词典或参考模型库,其中存放的是可能的词条序列(人为设置),作为独立于语音特征矢量,即词条序列在相应语言库中出现的概率;
声学模型:对声学单元建模,每个声学元素由连续的多个状态和状态之间的转移组成,用概率密度函数状态转移概率。可近似理解为一套数据结构和数学操作,实现的是进来一个声音单元(可以是音素、字、词、句),输出一组二进制序列/向量。这里以经典的隐马尔可夫-高斯HMM-GMM统计模型为例(现在许多用DNN替代GMM)。声学模型输出条件概率序列标记为;
语言模型:声学模型智能识别某段音素序列,不能识别词语。语言模型描述词语之间语法规则,通过概率密度分布函数来识别词条。语言模型有基于文法规则和统计类型的,后者是目前的主流,例如N元文法N-gram模型,就是根据前面n个音素预测第n+1音素。实际中需要用到平滑和剪枝算法,不详述。语言模型的输出是先验概率;
解码器:对矢量序列按照统计准则(贝叶斯等)计算条件概率,通常用Viterbi算法实现,动态规划的最优化选择,原理是搜索最大概率状态序列进行求解,具体不详述。
声学模型输出条件概率序列标记为,输出语言模型输出先验概率,语音词典可能的词条序列,有了这三个数组,我们就可以得到语音识别结果。
对于连续语音识别的过程,可以理解为:经过MFCC得到的特征序列进入声学模型;声学模型中,每个字词都有对应的HMM等参数,通过声学特征对字词进行搜素得到特征序列的待定字词;候选字词进入语言模型,通过词法规则和语言模型得到待定词句;再由句法等语言模型搜索得到完整的识别语句。
语料准备:人工智能,是用人工的数据“喂”出的智能。模型的训练需要提前准备大量的语音语料和文本语料,类型包括通用领域和特定领域。
语料处理:语料需要清洗和标注,包括元文本标准、重音标注、词法标注、句法标注、语义标注等。
语音助手主要解决听和说两个功能。其中听的话要依托自然语言处理技术,入声检测,回音消除,唤醒词识别,麦克风阵列处理,语音增强。语音识别的过程需要经历特征提取、模型自适应、声学模型、语言模型、动态解码等多个过程。 自然语言处理,语音识别的过程需要经历特征提取、模型自适应、声学模型、语言模型、动态解码等多个过程。
在智能出行方面,AI语音技术也是有很大的用处,而且在车载领域存在刚需。从最早的语音导航,到如今的车载语音控制系统,AI语音交互提供了包括车辆控制、社交以及娱乐等多种全新的交互方式,让驾驶员的注意力不再集中在各种繁杂的设置以及按钮上,在提升驾驶体验的同时能够在一定程度上增强行车的安全性。与传统车载系统通过按键或者屏幕操控不同,多模态融合检测、智能语音交互、多屏互动手势操作等一系列技术,将成为下一代智能座舱的标配。由于车内环境相对稳定,语音识别率高,因此座舱内是部署语音交互的极佳落地场景。
在智能家居方面,AI语音技术使我们的智能家电越来越好用。现在的智能家电能将“AI语音+大数据+深度学习”结合起来,让家电产品能听能说能看,了解用户需要什么,从而让使用户脱离手机、遥控器。能直接与机器进行听、说、看的自然交互,让智能家电更具有人性化。这种AI语音智能技术还为生活娱乐产品的应用操作带来了极大的便利。
目前,智能音箱作为所有智能家居交互的入口,扮演着一个重要的角色,除了常规的日程设置、音乐播放、天气等信息查询,智能音箱还可以控制灯光、空调、电视、窗帘等。还有现在有部分电视内嵌了声纹识别技术,电视会根据不同的音色识别到不同的角色(如:男性、女性、儿童),从而提供个性化视觉及内容推送服务。用户想看电影但不知道看什么,对电视说“我想看电影”,那么电视会根据识别到的人不同,而显示推荐出不同的内容,并且能控制非注册在系统中的人员不能操控。(部分摘录自)
在智能教育方面,AI语音技术可以作为课堂质量辅助和线上虚拟两部分。课堂质量辅助通过融合语音、视觉及文字技术辅助教师授课,实现实时字幕转录、重点内容快速定位、课堂数据分析等。尤其是新冠疫情以来,线上教学的需求量越来越大,基于AI语音交互的虚拟教师结合VR技术,可以摆脱教师人数的限制,一对一授课,并进行精准分析,提升学生学习的效果。语音测评和人机对话技术结合语义技术应用到普通话、古诗词及外语教学中,可以快速纠正发音韵律及语法错误,并且逐渐被应用到考试场景中。
在智能医疗方面,AI语音技术帮助医院和医疗机构提高了医疗服务的质量。新冠疫情、经济增长放缓、竞争加剧等多重挑战下,企业加速应用人工智能进行智能化建设,但仍面临诸多挑战。之前很多医院初期的随访工作是通过电话随访,人工坐席外呼工作量大,导致随访工作流于形式,随访流程繁杂,医生参与率低。而语音对话机器人的出现,非常适合解决医疗市场的长期低效率问题,在降低成本、减少医护人员时间负担的同时,能为患者带来不一样的体验提升。过去,传统的随访都要医护人员挨个拨打病人的电话询问患者的术后状况,并做记录。比如,医院日间手术平均每天出院病人在120人次以上,而每位病人一般在术后24-48小时要进行一次随访,就意味着医务人员每天要花9-12个小时用于电话随访,这给医院带来了巨大的随访工作量,而AI语音随访可以做到每天无间断、全覆盖随访,一天内可完成400-1000人次的随访工作,极大的提高了随访的工作量。数据摘录自《人工智能语音外呼系统在医学的运用》。
智能语音助手可根据客户需求构建支持语音交互能力,且具备知识库、任务型对话、多轮对话、表格问答、自动文本星空体育 星空体育平台生成、多模态等多种对话机器人能力的AI助手,赋能不同行业客户。产品具有很多优势,满足客户为客户量身定制,满足客户需求量身定制智能语音机器人;使用业界领先的自然语言算法,理解大量知识技术能力十分强;打通语音交互能力,一个接口搞定语音识别和对话能力;应用场景也十分广泛,比如大屏语音助手和应用对话助手。