

新闻资讯
质量为本、客户为根、勇于拼搏、务实创新
语音识别作为解放人类双手的沟通方式,一直是人类与机器进行交流的最佳方式。随着科学技术的不断进步,语音识别技术在生活中的应用越来越广泛,那么,什么是语音识别技术?原理是什么?本文将具体介绍。
语音识别(Automatic Speech Recognition,ASR)技术也称自动语音识别技术,是指机器通过识别和理解过程将语音信号转化为文本或指令的技术。语音识别以语音为研究对象,涉及到数字信号处理、计算机、模式识别、语音学、语言学、心理学、生理学、数理统计学等多门学科领域,是一门综合性很强的技术,在军事、交通、医学、工业、商业等领域都有着广泛的应用。语音识别的目标是让机器能够像人一样准确理解语音信号所承载的信息,从而实现人机交互。语音识别系统可以分成三类:孤立词语音识别系统、连接词语音识别系统与连续语音识别系统。

语音识别技术的研究最早开始于20世纪50年代,1952年贝尔实验室研发出了10个孤立数字的识别系统。从20世纪60年代开始,美国卡耐基梅隆大学的Reddy等开展了连续语音识别的研究,但是这段时间发展很缓慢。1969年贝尔实验室的PierceJ甚至在一封公开信中将语音识别比作近几年不可能实现的事情。
20世纪80年代开始,以隐马尔可夫模型(hiddenMarkovmodel,HMM)方法为代表的基于统计模型方法逐渐在语音识别研究中占据了主导地位。HMM模型能够很好地描述语音信号的短时平稳特性,并且将声学、语言学、句法等知识集成到统一框架中。此后,HMM的研究和应用逐渐成为了主流。例如,第一个“非特定人连续语音识别系统”是当时还在卡耐基梅隆大学读书的李开复研发的SPHINX系统,其核心框架就是GMM-HMM框架,其中GMM(Gaussianmixturemodel,高斯混合模型)用来对语音的观察概率进行建模,HMM则对语音的时序进行建模。
20世纪80年代后期,深度神经网络(deepneuralnetwork,DNN)的前身——人工神经网络(artificialneuralnetwork,ANN)也成为了语音识别研究的一个方向。但这种浅层神经网络在语音识别任务上的效果一般,表现并不如GMM-HMM模型。
20世纪90年代开始,语音识别掀起了第一次研究和产业应用的小高潮,主要得益于基于GMM-HMM声学模型的区分性训练准则和模型自适应方法的提出。这时期剑桥发布的HTK开源工具包大幅度降低了语音识别研究的门槛。此后将近10年的时间里,语音识别的研究进展一直比较有限,基于GMM-HMM框架的语音识别系统整体效果还远远达不到实用化水平,语音识别的研究和应用陷入了瓶颈。
2006年Hinton]提出使用受限波尔兹曼机(restrictedBoltzmannmachine,RBM)对神经网络的节点做初始化,即深度置信网络(deepbeliefnetwork,DBN)。DBN解决了深度神经网络训练过程中容易陷入局部最优的问题,自此深度学习的大潮正式拉开。
2009年,Hinton和他的学生MohamedD将DBN应用在语音识别声学建模中,并且在TIMIT这样的小词汇量连续语音识别数据库上获得成功。
2011年DNN在大词汇量连续语音识别上获得成功,语音识别效果取得了近10年来最大的突破。从此,基于深度神经网络的建模方式正式取代GMM-HMM,成为主流的语音识别建模方式。

(6)按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成。
(7)结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
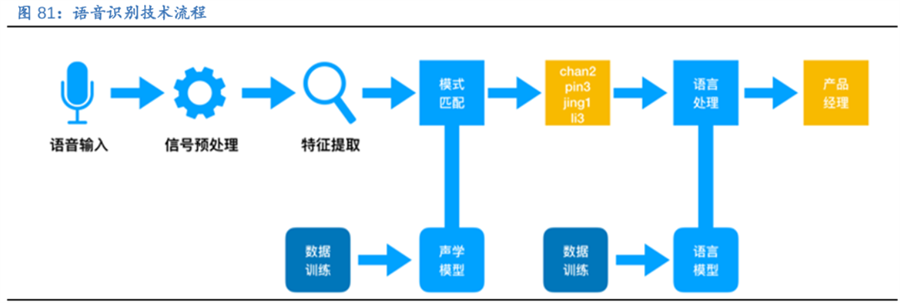
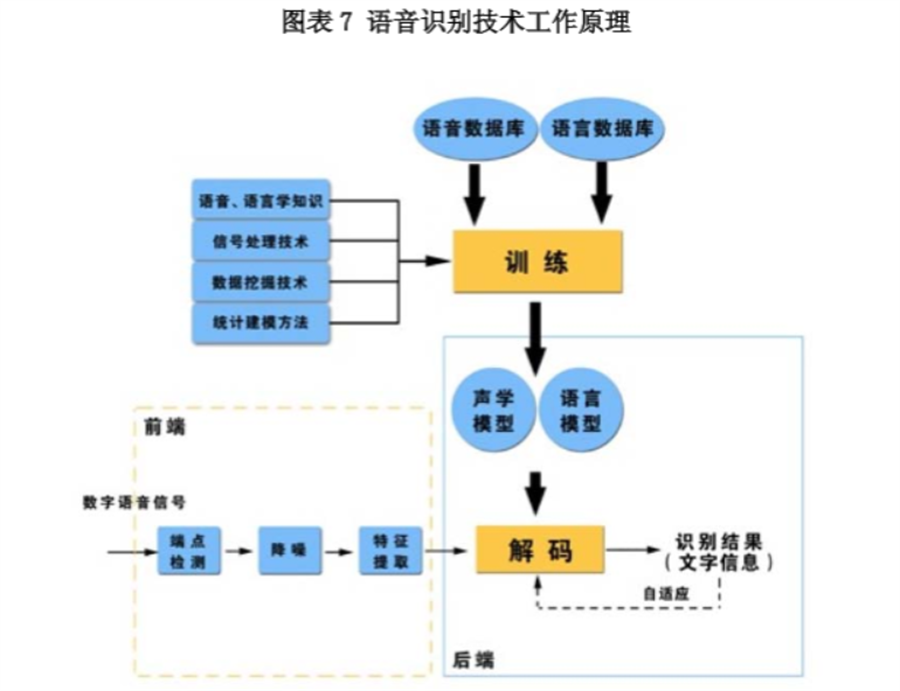
所谓语音识别,就是将一段语音信号转换成相对应的文本信息,系统主要包含特征提取、声学模型,语言模型以及字典与解码四大部分,其中为了更有效地提取特征往往还需要对所采集到的声音信号进行滤波、分帧等预处理工作,把要分析的信号从原始信号中提取出来;之后,特征提取工作将声音信号从时域转换到频域,为声学模型提供合适的特征向量;声学模型中再根据声学特性计算每一个特征向量在声学特征上的得分;而语言模型则根据语言学相关的理论,计算该声音信号对应可能词组序列的概率;最后根据已有的字典,对词组序列进行解码,得到最后可能的文本表示。
首先,声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如WindowsPCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。
要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现。
分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。
至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。
音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。
那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据。
但这样做有一个问题:每一帧都会得到一个状态星空体育登录入口 星空体育在线官网号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
解决这个问题的常用方法就是使用隐马尔可夫模型(HiddenMarkovModel,HMM)。
这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。
那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。
搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
语音识别技术在PC机/移动终端上的应用范围较广,目前可以用语音识别来进行身份认证、编辑文本或者语音控制。典型的包括语音输入法、语音助手、音频识别软件等。
应用的范畴广,根据市场需求考虑不同的嵌入式硬件平台,目前嵌入式语音识别系统主流是智能手机、车载系统、智能家居、智能终端的集成应用。
语音识别技术应用于企业自动语音服务,可以为企业提供- -种智能化的并且相对安全的自动服务方式。包括,企业的用户服务中心、电话银行、股票交易、电子商务等应用领城。
把语音技术与Web应用结合,例如语音浏览器、语音搜索引擎,网上语音聊天室及语音网游等。
为安全部门提供声纹识别应用方案,进行自动的身份辨认,在国家安全、侦破等特殊领域,市场专业性强,进入壁垒高,同业竞争者很少。

以上梳理了语音识别技术的定义、原理、发展历程等信息,希望对你有所帮助,当前,随着人机交互技术的发展,语音识别技术有了更广阔的发展空间,是未来科技的一大趋势。如果你想了解更多相关内容,敬请关注三个皮匠报告行业知识栏目。
本文由作者2200发布,版权归原作者所有,禁止转载。本文仅代表作者个人观点,与本网无关。本文文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
微博(2023年环境、社会和治理(ESG)报告(英文版)(114页).pdf
思爱普(SAP):2024商业数据编织研究报告(英文版)(14页).pdf
赛默飞世尔科技公司(THERMO FISHER SCIENTIFIC)2023年年度报告(英文版)(96页).pdf
世邦魏理仕:2024年第三季度澳大利亚高端住宅市场价值评估洞察报告(英文版)(13页).pdf
清华五道口:2024清华五道口首席经济学家论坛-全球产业结构变革与经济展望(87页).pdf
易点天下:2024AI营销白皮书-以AI数据寻求AGI时代下的出海营销增量新范式(37页).pdf
电子发烧友:2024年AI服务器和AI PC趋势解读报告(38页).pdf