

新闻资讯
质量为本、客户为根、勇于拼搏、务实创新
实时语音识别接口采用websocket协议的连接方式,边上传音频边获取识别结果。可以将音频流实时识别为文字,也可以上传音频文件进行识别;返回结果包含每句话的开始和结束时间,适用于长句语音输入、音视频字幕、直播质检、会议记录等场景。
WebSocket 是基于TCP的全双工协议,即建立连接后通讯双方都可以不断发送数据。
发送数据帧:Sending Data Frame, 类似包的概念,指一次发送的内容 。从客户端到服务端。
接收数据帧: Receiving Data Frame, 类似包的概念,指一次发送的内容 。从服务端到客户端。
通常WebSocket库用需要用户自己定义下面的3个回调函数实现自己的业务逻辑。
连接成功后的回调函数: { #通常需要开启一个新线程,以避免阻塞无法接收数据 2.1 发送开始参数帧 2.2 实时发送音频数据帧 2.4 发送结束帧 } 接收数据的回调函数 { 2.3 库接收识别结果,自行解析json获得识别结果 } 服务端关闭连接的回调函数 { 3. 关闭客户端连接, 部分库可以自动关闭客户端连接。 }
连接地址(WebSocket URI):参数 sn由用户自定义用于排查日志,建议使用随机字符串如UUID生成。 sn的格式为英文数字及“-” ,长度128个字符内,即[a-zA-Z0-9-]{1, 128}
使用中文多方言模型(pid:15376)时,需要在参数中加入user:XXX(参数任意)
目前中文多方言模型(pid:15376)可同时支持中文、粤语、四川话和东北话
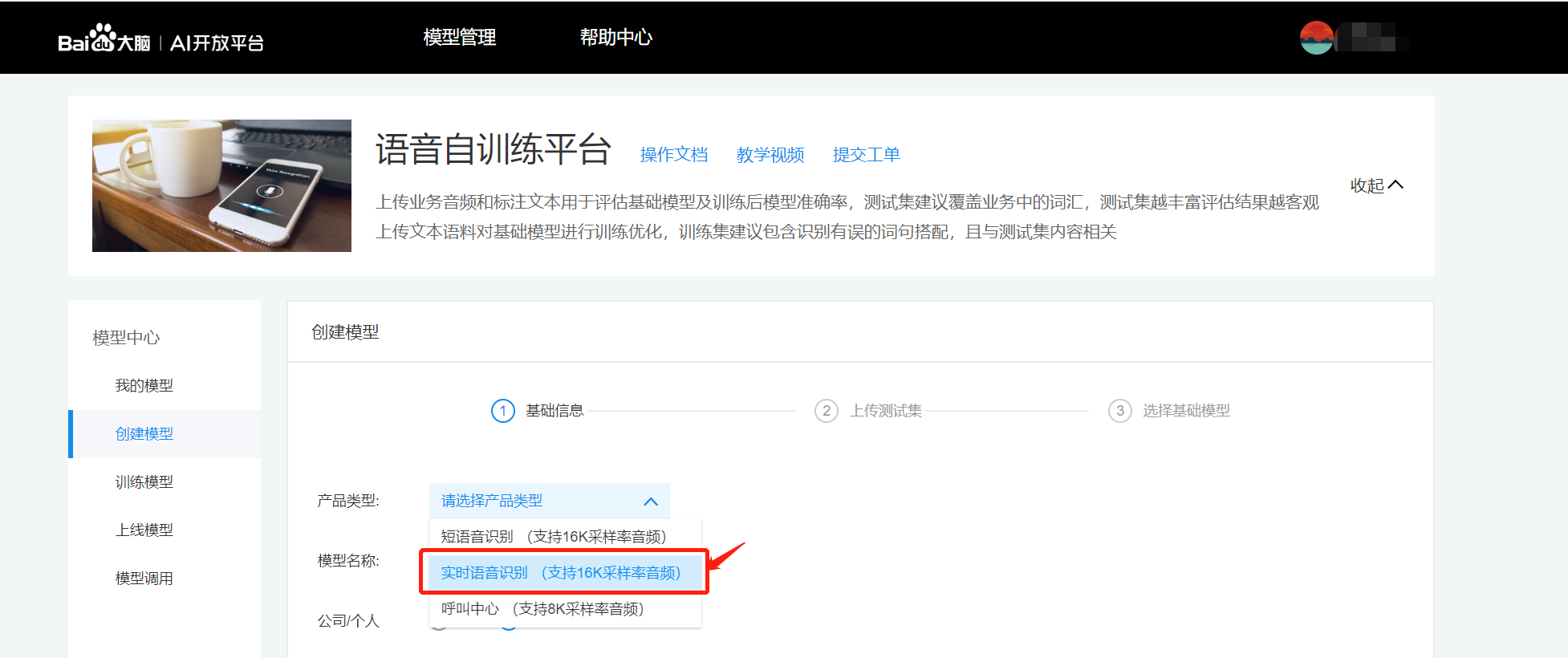
训练后的模型注意必须填写上线模型的模型参数,可在自训练平台的模型调用模块进行查看。
这里需要注意,服务端5s没有收到音频数据会断开并报错,发送间隔控制在5s以内
内容是二进制的音频内容。 除最后一个音频数据帧, 每个帧的音频数据长度为20-200ms。 建议最佳160ms一个帧,有限制的也建议80ms。
实时语音识别api 建议实时发送音频,即每个160ms的帧之后,下一个音频数据帧需要间隔160ms。即:文件,此处需要sleep(160ms) 如果传输过程中网络异常, 需要补断网时的识别结果,发送的音频数据帧之间可以没有间隔。具体见下文“断网补发数据”一节
取消与结束不同,结束表示音频正常结束,取消表示不再需要识别结果,服务端会迅速关闭连接 示例:
注意帧的类型(Opcode)是Text, 使用json序列化 正常情况下不需要发这个帧,仅在网络异常的时候,需要补传使用,具体见“断网补发数据”
注意需要接收的帧类型(Opcode)是Text, 本接口不会返回Binary类型的帧。 text的内容, 使用json序列化
一段音频由多句话组成,实时识别api会依次返回每句话的临时识别结果和最终识别结果
服务端报错如-3005错误码,是针对的是一个句子的,其它句子依旧可以识别,请求是否结束以服务端是否关闭连接为准。 具体错误码含义见文末“错误码“一节
一句话的开始时间及结束时间:识别过程中,百度服务端在每句话的最终识别结果中带有这句话的开始和结束时间。最终识别结果是指type:FIN_TEXT,即一句话的最后识别结果,包括这句话的报错结果。
断网补发数据的目的是将一个语音流,在网络不佳的情况下,通过自己的代码逻辑拼接,使得多次请求的结果看上去像一次。
简单来说就是哪里断开,从哪里开始重新发一次请求,“哪里”=最后一次接收的“end_time”。服务端对每个请求独立,需要自行拼接补发数据的请求时间。
如果发送过程中,比如在第七句e7之后,网络抖动或者遇见其它错误。但是为了不影响最终的用户体验,期望连续的10个句子的识别结果。
此时,可以发起一个新的请求,从e7开始发数据,在,语音数据帧之间不需要sleep。
如果超过5s没有发送音频数据给服务端,服务端会下发报错并结束连接,建议至少2s 发送一次。
开始一次新请求, 从缓存的音频数据中找到7000ms(224000bytes)以后的数据,发送给服务端。每个帧160ms星空体育官方入口 星空体育官网的音频数据,补数据时,每个帧之间不需要间隔sleep。
新请求的start_time和end_time可以加上7000ms,然后展示给用户
如果补发数据过大,新请求过快结束,在新请求结束时,需要补type=HEARTBEAT心跳帧,建议2-3s发一次,避免5s服务端读超时。